Welcome to Poseidon¶
Poseidon is an easy-to-use and efficient system architecture for large-scale deep learning.
This distribution of Poseidon uses the Tensorflow 0.10 client API.
Introduction¶
Poseidon allows deep learning applications written in popular languages and tested on single GPU nodes to easily scale onto a cluster environment with high performance, correctness, and low resource usage. This release runs the TensorFlow 0.10 api on distributed GPU clusters - greatly improving convenience, efficiency and scalability over the standard opensource TensorFlow software.
Performance at a Glance¶
Poseidon can scale almost linearly in total throughput with additional machines while simultaneously incurring little additional overhead.
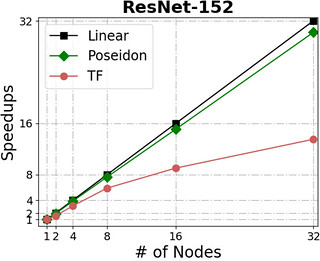
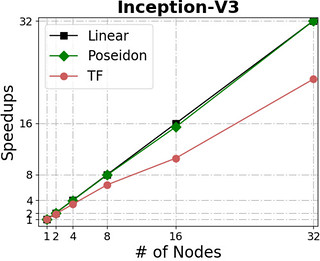
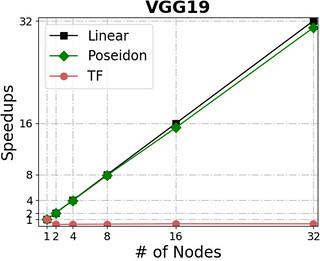
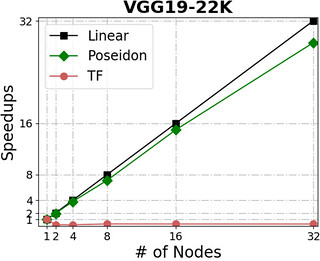
The following figures show Poseidon’s performance on four widely adopted neural networks (see the table for their configurations) using distributed GPU clusters. All of these neural networks use the TensorFlow api (0.10), and the benchmarks compare the Poseidon software against the standard TensorFlow engine.
| Name | #parameters | Dataset | Batchsize (single node) |
|---|---|---|---|
| Inception-V3 | 27M | ILSVRC12 | 32 |
| VGG19 | 143M | ILSVRC12 | 32 |
| VGG12-22k | 229M | ILSVRC12 | 32 |
| ResNet-152 | 60.2M | ILSVRC12 | 32 |
For distributed execution, Poseidon consistently delivers near-linear increases in throughput across various models and engines. For example, Poseidon registered a 31.5x speedup on training the Inception-V3 network on 32 nodes, which is a 50% improvement upon the original TensorFlow (20x speedup). When training a 229M parameter network (VGG19-22K), Poseidon still achieves near-linear speedup (30x on 32 nodes), while distributed TensorFlow sometimes experiences negative scaling with additional machines.
Contact¶
- Adam Schwab - adam.schwab@petuum.com
- Hong Wu - hong.wu@petuum.com
- Hao Zhang - hao.zhang@petuum.com